Qeplar is a sovereign product operating system. Specialist AI agents cover every domain of your product org — strategy, delivery, revenue, operations, go-to-market, support. They observe your data, deliberate in real meetings, execute the work humans don’t need to, and prove their own accuracy every quarter. It refuses to pile work on overloaded teams. It retires stale priorities. It learns what works for your org — for years. On your server. Not the cloud.
Six continuous stages. No one presses start. The loop is always running. Observe, check capacity, act, trade off, sunset what’s stale, learn from the outcome. Then do it again, with more memory than last time.
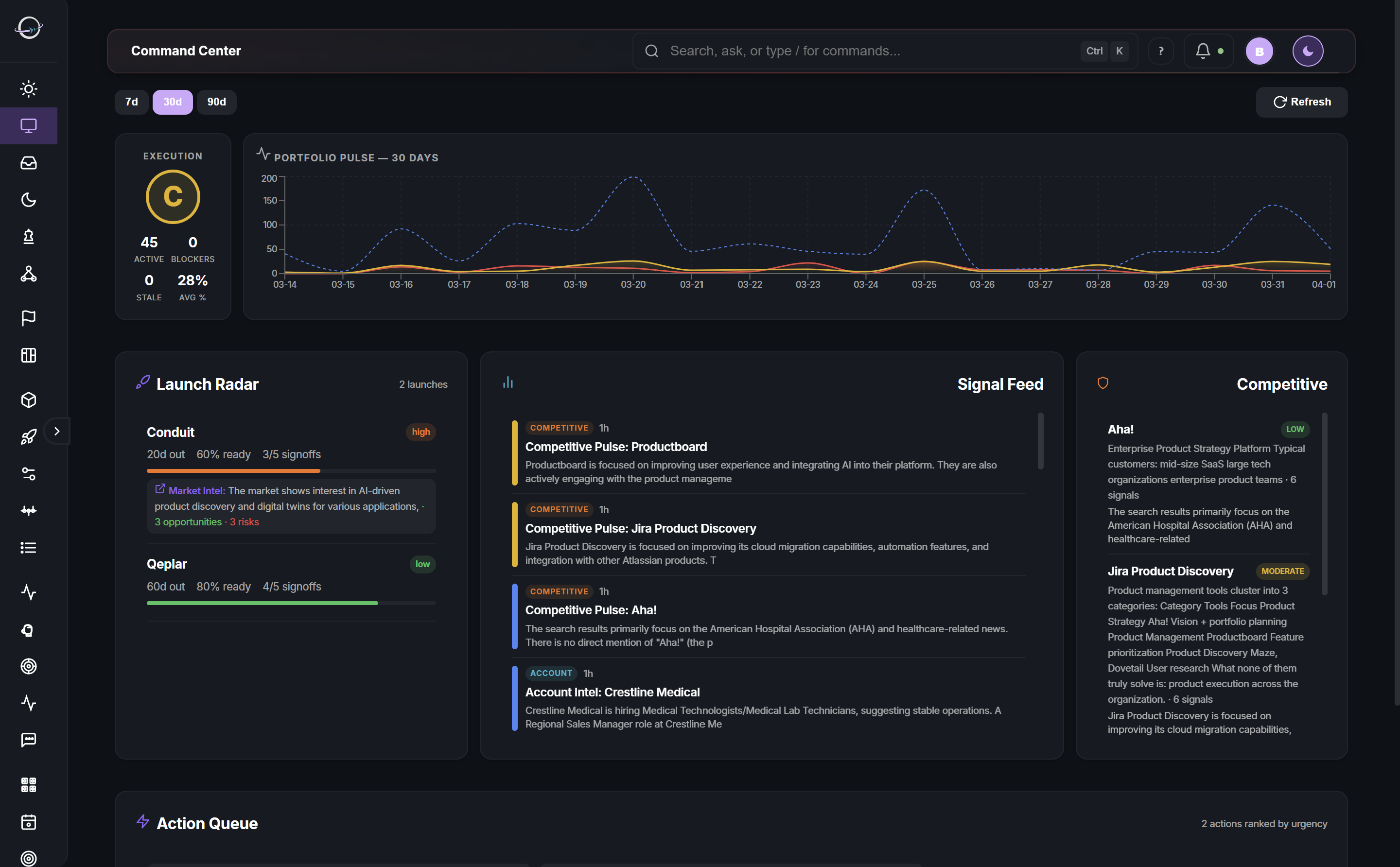
Specialist agents watch your launches, priorities, sprints, VoC, competitors, field support, and market news. Every signal is scored by relevance to each user and stored with provenance.
Before creating work, the capacity engine checks historical execution hours, current load, team velocity. If a team is over capacity, the system proposes trade-offs instead of piling on.
Competitive research, VoC summarization, changelog drafting, meeting minutes, alignment scoring, release notes, Hubble signal correlation — Qeplar does it before you arrive.
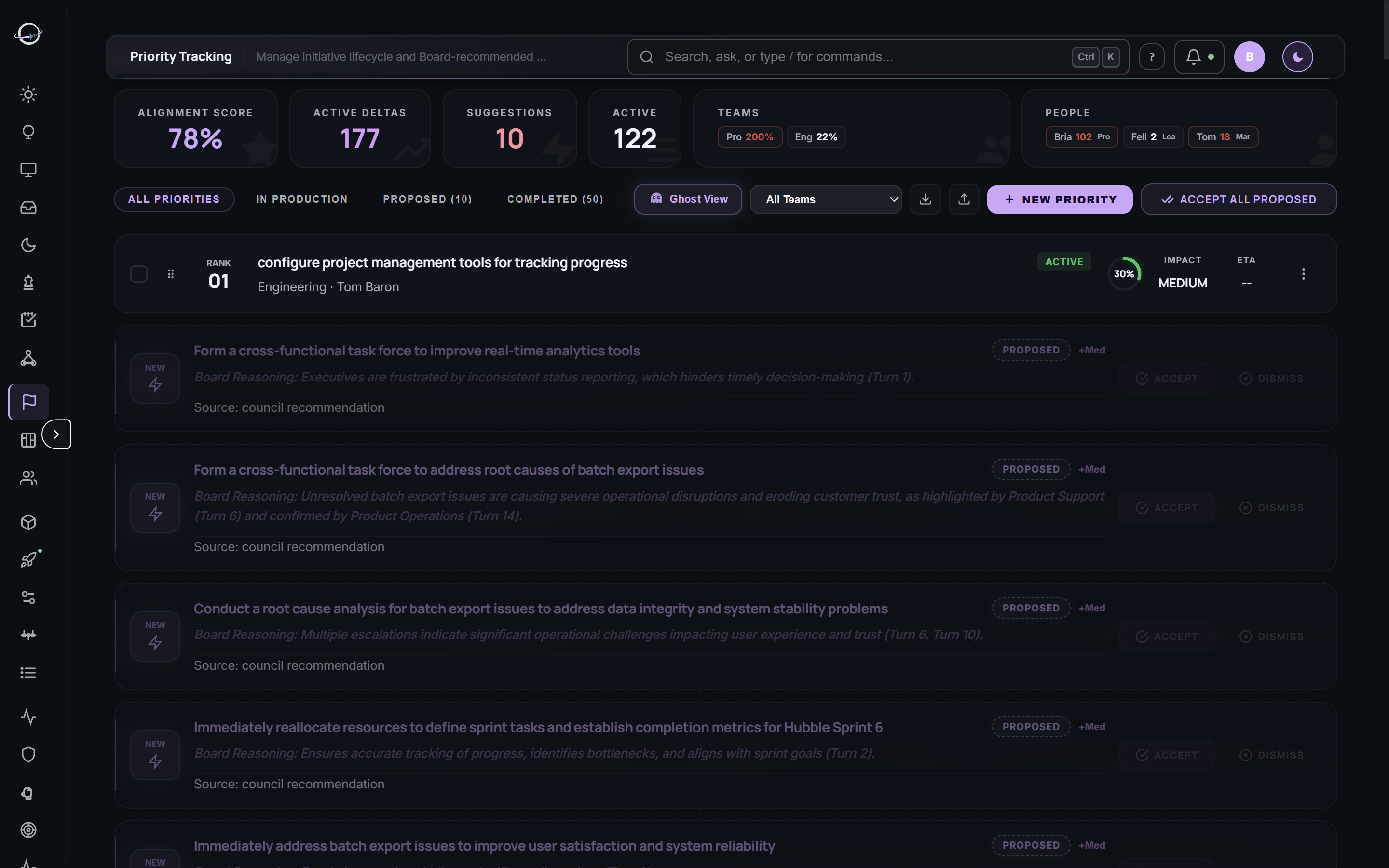
Recommendations appear inline where you work — never as a separate panel. Accept, defer, or dismiss each one. Every decision is logged with reasoning, so the reason survives personnel changes.
Priorities with zero progress for 60+ days surface as sunset proposals. Management reviews the facts and decides: sunset, defer, or reactivate. Nothing rots silently in the backlog anymore.
30, 60, 90 days, 1 year, 3 years later, Qeplar asks “did that work?” Agents that are accurate get more weight. Agents that miss get less. The system proves it’s getting smarter.
Your customer interviews are proprietary intelligence. Your competitive positioning took years to build. Your roadmap is the work product of every strategic decision your organization has made. Every cloud product tool processes all of it on vendor-operated infrastructure — and the only way to confirm what happens to your data is to take the vendor’s word for it.
Qeplar runs on your hardware. Your database. Your local LLM — Ollama with qwen2.5, gemma, or whatever model passes your security review. Zero ports open. Runs fully disconnected by default. Approved for defense, aerospace, medical, and regulated industries on day one.
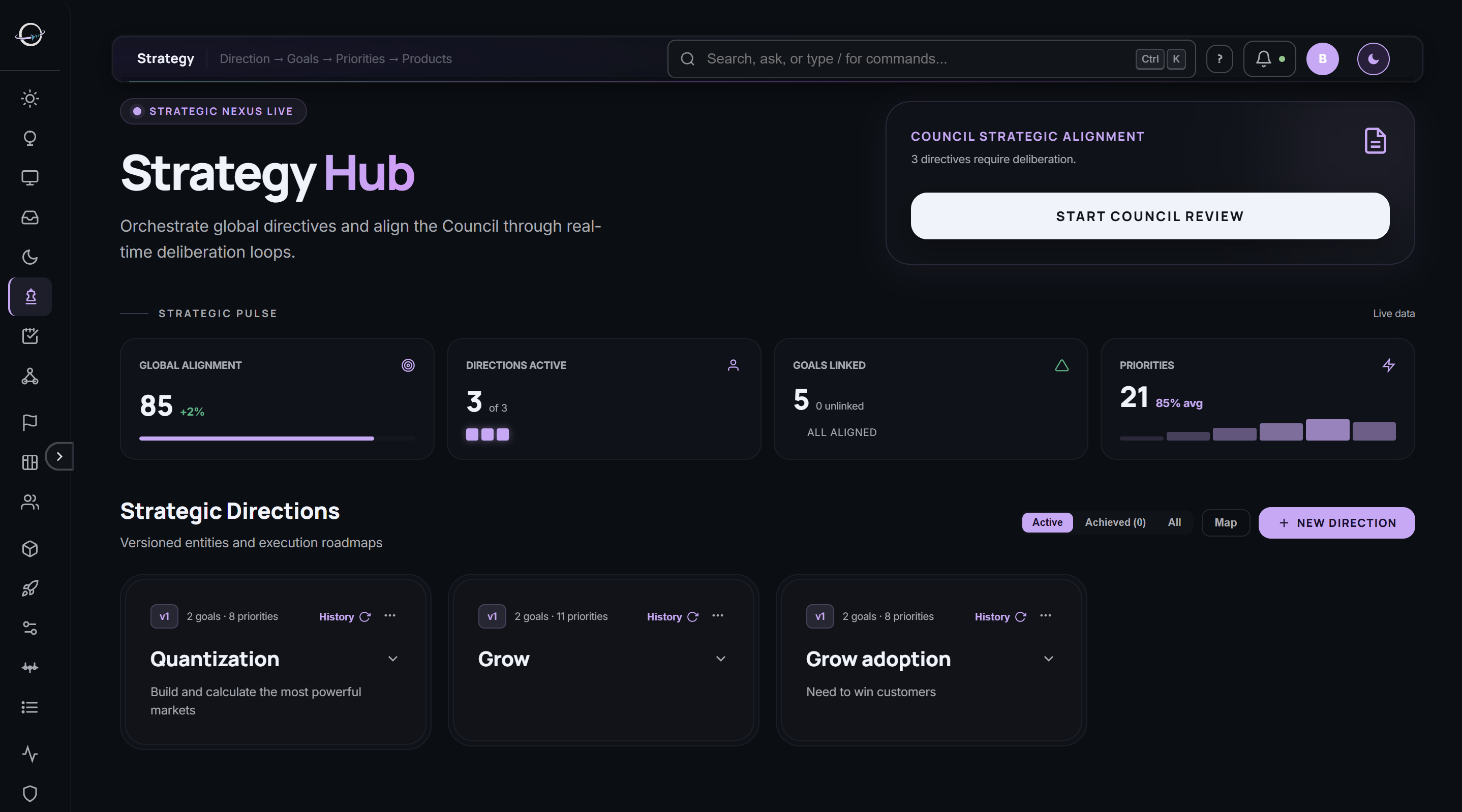
Specialist agents across three tiers. The Board deliberates in real meetings. Background watchers never sleep. External scanners read the market for you. They argue. They revise. They converge — or they tell you where they didn’t. Every deliberation draws on your organization’s memory — past decisions, customer interviews, prior meetings — retrieved by meaning and cited by source.
Each agent has a defined persona, domain scope, and color. Your admin can edit any agent, create new ones for your industry (Regulatory, Security, Compliance), test against live data before activating, and watch their accuracy scores accumulate over time.
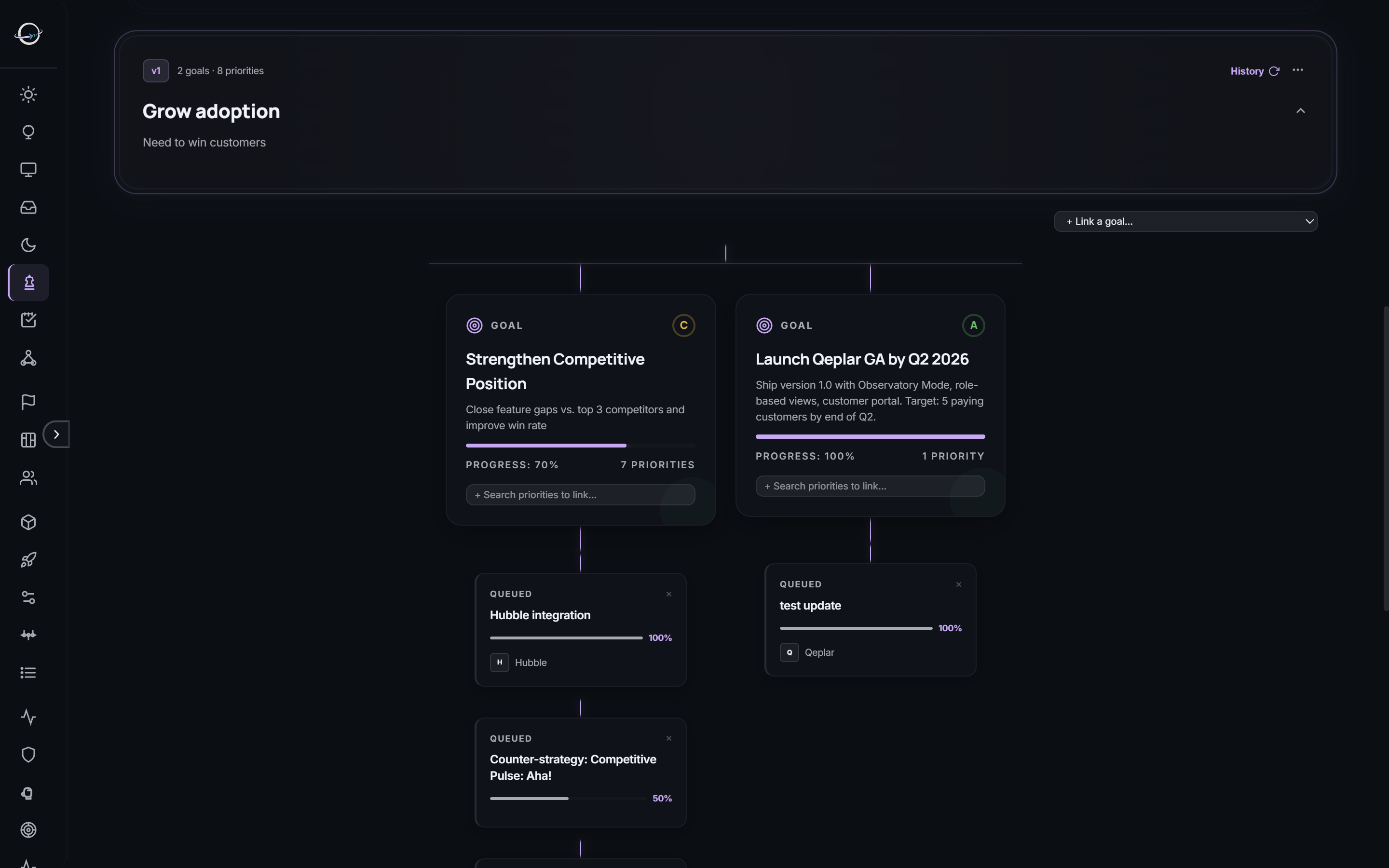
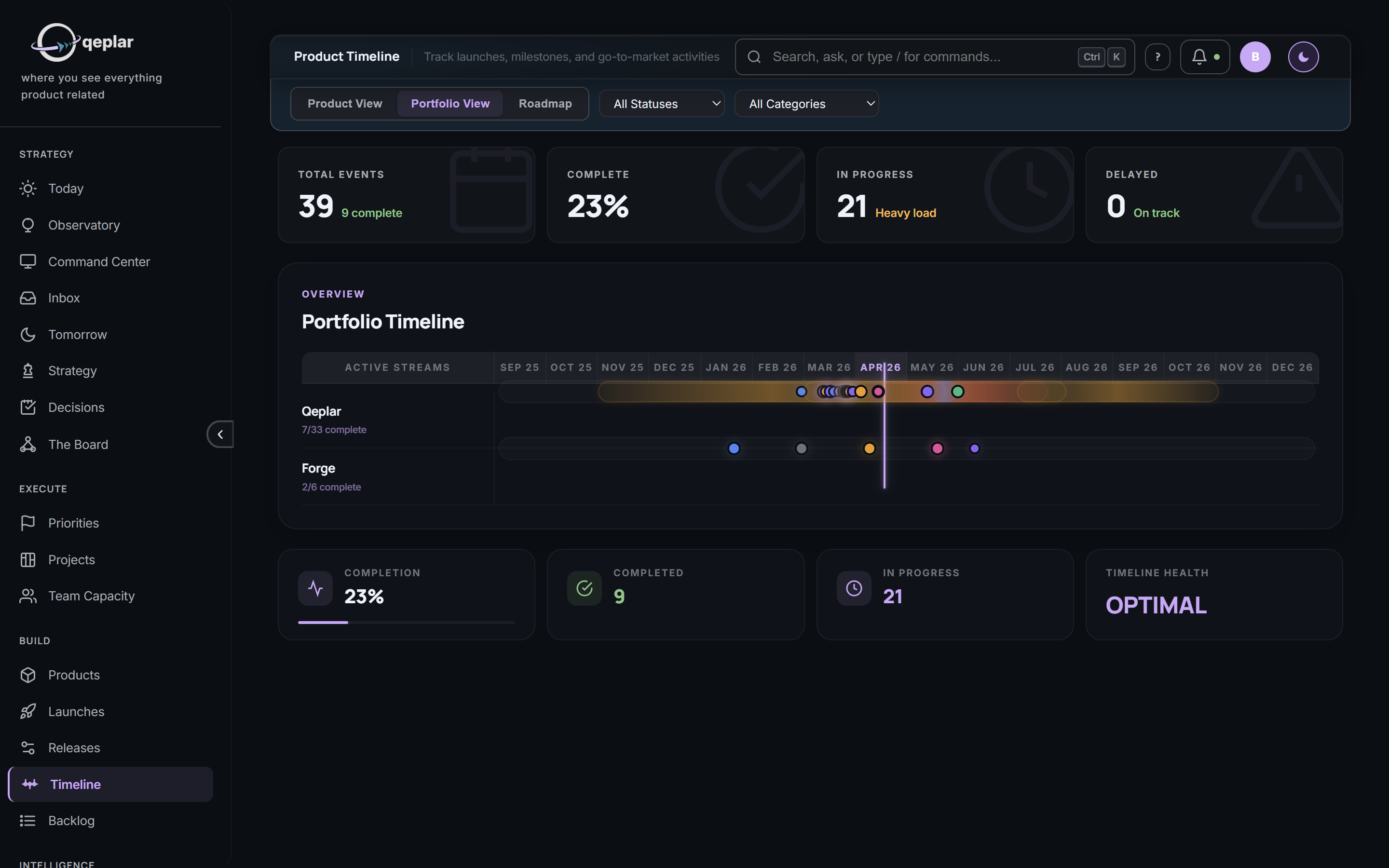
Real screens from a live deployment. No mockups, no renderings.
“Why did we defer mobile onboarding last year?” “What did support tell us about the Q2 launch?” “Which customers mentioned the competitor in their last interviews?” Ask the question. Get an answer with citations back to the exact decisions, customer interviews, and meetings that informed it.
No hallucinated context. No generic AI paragraphs. Every sentence cites the decision, customer interview, meeting, or strategic direction it came from. One click drills to the original.
A new hire asks “what do I need to know about this product?” on day one and inherits years of context — customer pain, killed features, competitive wins, strategic pivots. Institutional knowledge stays when people leave.
Every question, every answer, every citation is processed by your local AI on your server. Nothing goes to a vendor. Nothing becomes training data for someone else’s model.
Every recommendation gets validated at seven cadences. Every forecast gets compared to reality. Every agent accumulates a track record. You don’t have to trust that the AI is getting smarter — you see the numbers, per agent, per domain, per quarter.
Count the hours your team currently spends on competitive research, VoC summarization, launch coordination, and stale backlog triage. Against a single annual license, that math recovers itself in the first quarter of deployment.
Hubble is where your customers live. Qeplar is where your product team works. The bridge between them runs both directions — every support interaction becomes a structured product signal, and every shipped fix drops back into the live sessions that asked for it. No exports. No ticket queue. No copy-paste. One continuous feedback loop with privacy scrubbed at the boundary and every byte in an audit log.
Live support chat, knowledge base, equipment health, and — pushed in from Qeplar — launch phase, release notes, and the known issues that affect them. Customers never get asked for their serial number. They never need a second portal login. Launch transparency sits next to the chat window, not behind another credential.
Command queue with typing indicators and drag-to-reorder. Equipment context rail fed from Qeplar: product manifest, known fixes, live telemetry, canned responses, internal notes. Proactive KB suggestions in the chat sidebar. Chat-to-ticket AI draft at session close — title, description, category, tags, summary, confidence. Live pattern detection: same component breaking across tenants auto-escalates to engineering.
HMAC-SHA256 signed with key rotation and grace period. Tenant-scoped. Payloads run through the Intelligence Airlock before the Board sees them. Circuit breaker opens automatically on 5 consecutive failures. Every accepted and rejected request lands in the bridge audit log. Offline mode available for air-gapped deployments — queue and replay.
Every support interaction becomes a signal your product and content teams can act on. Customer demand shapes your knowledge base. Repeat issues auto-escalate to engineering. Published fixes reach in-session customers the moment they ship. Support stops being a cost center and starts being a product-data pipeline.
Most launch slips trace back to an upstream miss nobody surfaced. A dependency that went unnoticed. A handoff that never happened. A decision one team made without the teams it affected in the room. Qeplar makes every seam a first-class object — with owners, dates, and accountability.
Load, capacity, priorities, blockers, what they own, what they shipped, what’s coming due. Not a manager’s report — a live page, shared across the org. No more “what is that team working on” Slack questions.
“Engineering needs the spec by Oct 10.” “QA expects the build by Nov 3.” Dependencies and handoffs are logged as real objects — tracked, escalated, cascaded when they slip. The upstream miss becomes visible the moment it happens.
We deferred the feature. We killed the initiative. We chose the vendor. We reallocated the team. Every decision captures the rationale, the alternatives, and the teams affected. Six months later when someone asks “why?” — the answer is already there. And every significant decision gets validated out to three years against what actually happened.
Every feature you ship gets an adoption curve — by customer, by account, by time. Customers paying for a feature they never touch become a churn warning, not a surprise. High-adoption features correlate with CSAT automatically — you see which work actually moved the needle.
Ninety percent of launch slippage is organizational, not technical. It’s the handoff that didn’t happen, the decision the affected team never saw, the dependency nobody surfaced. Qeplar treats those as real objects with real owners — so the slip becomes visible the moment it’s possible, not the week of launch.
Every AI action has a tier. Every action has an undo. Nothing happens you didn’t allow.
Every one of these is built and running in production today. None of them are roadmap items.
We’re not a “Productboard alternative.” We’re what comes after tools that require your strategy to live in someone else’s cloud.
| Capability | Productboard | Aha! | Jira PD | ChatGPT for PM | Qeplar |
|---|---|---|---|---|---|
| Runs on your hardware | × | × | × | × | ✓ |
| Your data never leaves your building | × | × | × | × | ✓ |
| Autonomous execution (overnight work) | partial | × | × | × | ✓ |
| Capacity-aware (refuses overload) | × | partial | × | × | ✓ |
| Auto-sunset stale work | × | × | × | × | ✓ |
| Validates own accuracy (quarterly) | × | × | × | × | ✓ |
| Multi-agent deliberation (not single LLM) | × | × | × | × | ✓ |
| Launch readiness scoring | × | partial | × | × | ✓ |
| Predictive slip with revenue at risk | × | × | × | × | ✓ |
| Strategic direction versioning | × | × | × | × | ✓ |
| Live field intelligence bridge (14 signal types) | × | × | × | × | ✓ |
| Ghost suggestions inline with your work | × | × | × | × | ✓ |
| Per-agent + per-model accuracy tracking | × | × | × | × | ✓ |
| Outbound audit log (“what left the building”) | × | × | × | × | ✓ |
| Autonomy tiers + undo trail (every AI action reversible) | × | × | × | × | ✓ |
| Institutional memory you can query | × | × | × | × | ✓ |
| Cross-team dependencies & handoffs tracked | × | × | × | × | ✓ |
| Decision registry with outcome validation | × | × | × | × | ✓ |
| Per-customer feature adoption tracking | × | × | × | × | ✓ |
| Integrates with your existing tools | ✓ | ✓ | ✓ | × | ✓ |
| Roadmap & goals hierarchy | ✓ | ✓ | ✓ | × | ✓ |
Qeplar doesn’t promise it gets smarter. It proves it. Validated recommendations accumulate. Agent track records grow. Organizational patterns emerge. When someone leaves, their decisions, knowledge artifacts, and strategic DNA stay in the system.
Morning briefings, launch readiness grades, competitive alerts, sprint health, autonomous overnight work. The platform does your job before you open your calendar.
Five years of validated forecasts reveal which strategies produce results. The system knows your Q4 launches always slip two weeks, that competitive responses within 48 hours retain accounts 3× better. Per-agent, per-domain accuracy baselines you can bet on.
A decade of organizational intelligence survives every personnel change. When your VP of Product retires, their strategic DNA stays in the system. A new hire opens Qeplar on day one and inherits what took ten years to learn. No competitor can replicate that by switching tools.
Qeplar is early. When product leaders sit down with us, these are the questions we answer before anything else. We’re publishing them instead of fabricated testimonials — because prospects in this market can tell the difference.
Every deployment is different. Team size, integration needs, AI hardware, support requirements. We’ll walk through it together after you see the platform in action.
We’ll walk through the full platform on real hardware with your questions answered in real time. Launch readiness, agent deliberation, capacity blocking, validation pipeline — all live.
No — and that’s intentional. Qeplar operates at the strategy and launch intelligence layer above task management. It connects to Jira, GitHub, and Azure DevOps, pulling signals from your existing tools. Your developers keep their workflow. What changes is that product leaders and executives can finally see what all that work means for launch readiness, revenue, and competitive position — and the AI does the overnight work humans shouldn’t have to.
Productboard helps you decide what to build. Aha! manages roadmaps. Neither runs overnight work on its own. Neither blocks an overload before it happens. Neither grades its own recommendations 30, 60, 90 days later. Neither runs on your hardware. Qeplar is the next generation — a product operating system where specialist AI agents across every product domain observe, deliberate, act on your data, and prove their accuracy every quarter. And unlike both of them, your roadmap and competitive intelligence never leave your building.
Every recommendation Qeplar makes gets validated at seven cadences: 30 days, 60 days, 90 days, 6 months, 1 year, 2 years, 3 years. You rate whether it worked (or Qeplar infers it implicitly from outcomes). Scores roll up per agent, per domain, per LLM model. Inaccurate agents get weighted down in future synthesis. The impact dashboard shows hard numbers: accuracy % rolling 12 months, hours saved by autonomous execution, revenue retained from early competitive response. Every number is traceable back to specific recommendations. No vanity metrics.
Every team and person in Qeplar has a measured capacity — derived from 40h available minus meetings minus context switch time, adjusted by historical execution velocity. Before a new priority is assigned, Qeplar checks if the team is at or over capacity. If over, it proposes trade-offs: which priorities to defer, which to reassign, which to accept as a slip. Your PMs can’t blind-dump work anymore. Your people don’t burn out silently.
Everything runs on your hardware using local inference via Ollama. Your data never leaves your server. The Board reads your products, priorities, launches, VoC data, and integration signals — all stored in your on-premises database — and generates recommendations grounded in that context. Nothing is sent to OpenAI, Anthropic, Google, or any external service unless you explicitly enable external intelligence scanning (Serper/Gemini) — and even that can be toggled off for fully disconnected operation. Defense and aerospace deployments run air-gapped by default.
Day one: import products, priorities, launch data. The morning briefing reflects your actual state by day two. Week one: Board runs its first deliberation and generates its first autonomous work. Week two: predictive slip tracks your launches. Quarter one: first validation cadences fire and agent accuracy starts accumulating. Year one: the platform has enough data on your organization specifically to start surfacing patterns no human would track.
One afternoon. Provision a server meeting our sizing guide. Install Docker. Run the compose file we provide. After that, IT has nothing to maintain — Qeplar is self-contained. Updates are a single pull-and-restart. Remote access works through encrypted mesh networking — no VPN, no inbound ports, no firewall changes.
It stays. Every decision, interview, deliberation, and strategic direction is captured as a first-class object — not a Slack thread or a meeting memory. A new PM on day one can ask Qeplar “why did we defer this last year?” or “what do customers tell us about this product?” in plain English and get answers with citations to the original source. The institutional knowledge you paid years to accumulate does not walk out the door.
Yes. Dependencies between teams are real objects with owners and dates. Handoffs — spec-to-engineering, build-to-QA, release-to-marketing — are tracked as lifecycle events. When an upstream team slips, downstream teams see the cascade automatically. Every team has a shared page showing load, capacity, and open commitments. The organizational seam becomes visible the moment it’s possible, not the week of launch.
They’re looking at one piece of it. Qeplar is a complete product operating system — specialist agents across every domain, a validation pipeline that grades seven cadences out to three years, a capacity engine that blocks overload, a sunset engine that keeps backlogs clean, a forecast engine that corrects itself when it’s wrong, an organizational memory that survives personnel changes. Those all took years to build and years more to prove. A team of engineers could build a priority tracker in a month. They cannot build a sovereign product operating system while also shipping their actual product. And if they could, they’d still have no validated organizational intelligence to show for it on day one.